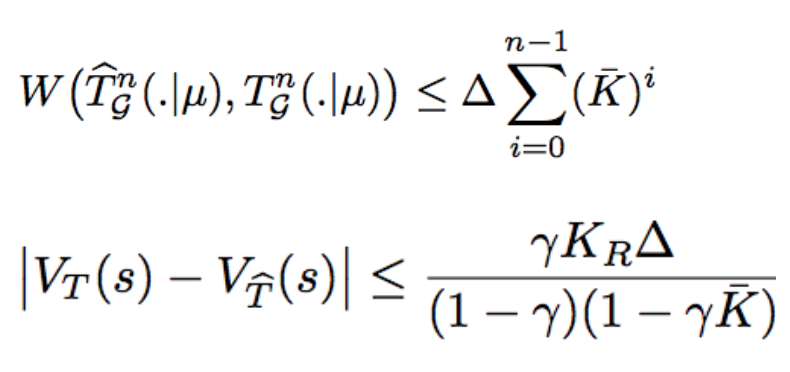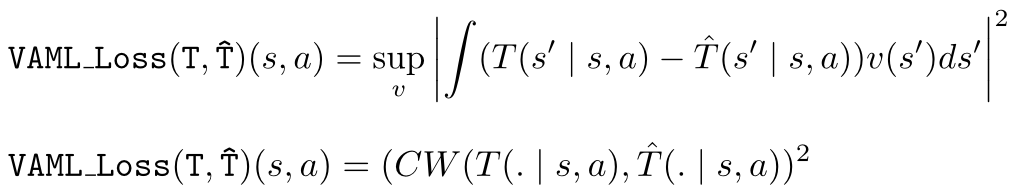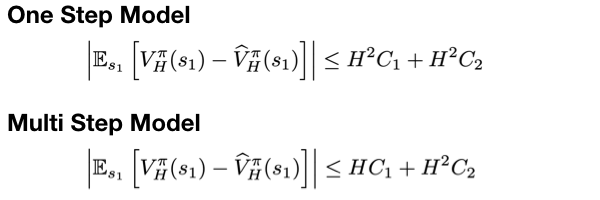Senior Researcher,
Microsoft Research, New York
Dipendra Kumar Misra
I am a machine learning researcher specializing in the field of natural language understanding, interactive learning (e.g., reinforcement learning), and representation learning. My main research agenda is to develop generalizable agents that can interact with the world using actions and natural language, and solve a range of tasks using reward, natural language feedback, or other types of feedback.
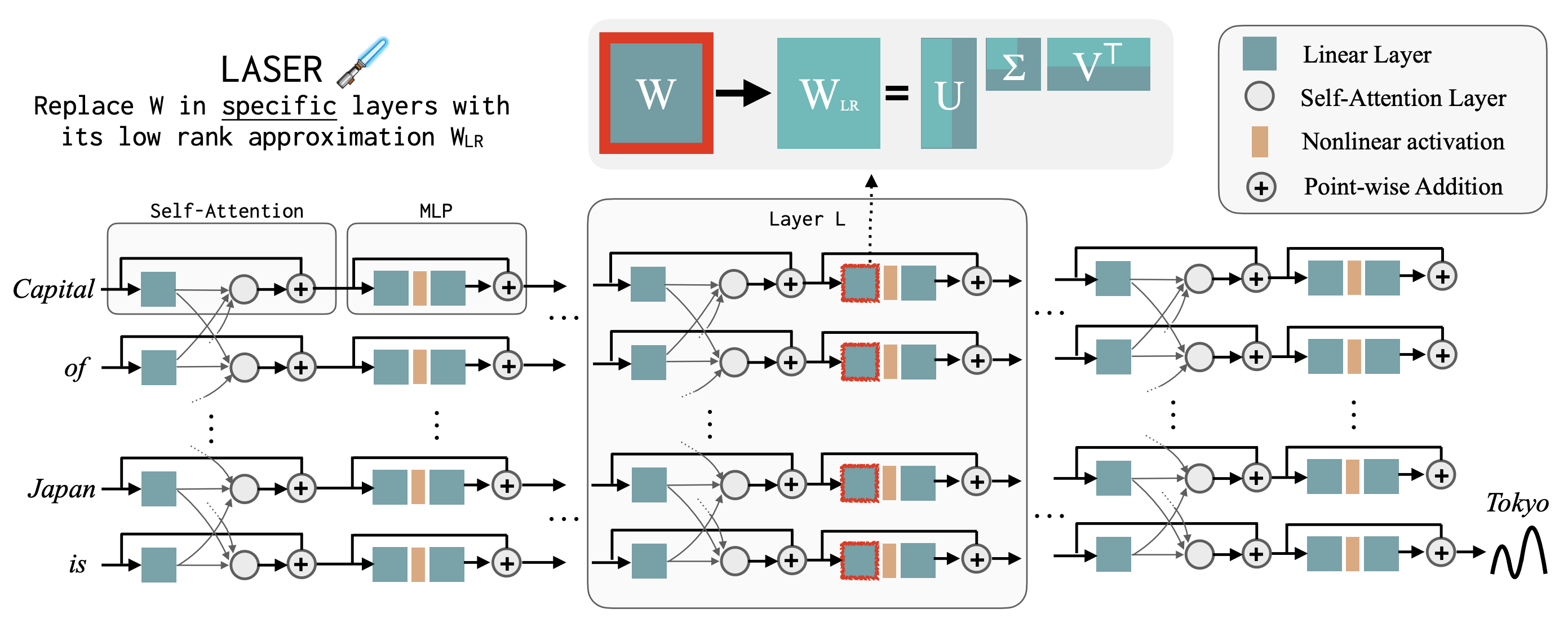
News: Our LASER paper got accepted at ICLR 2024, trended on Github python, and got featured in a Verge article!
My research agenda has the following main threads.
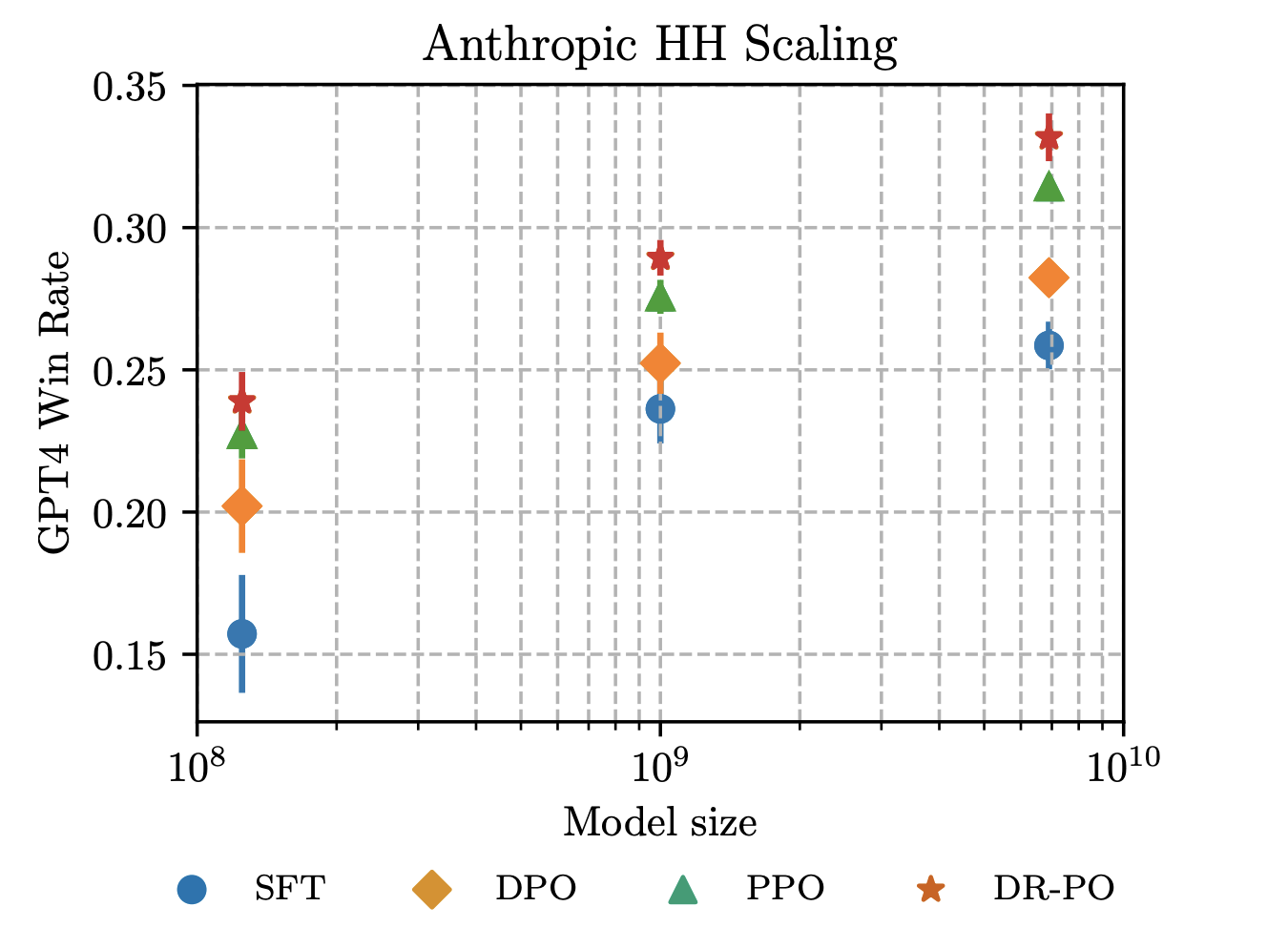
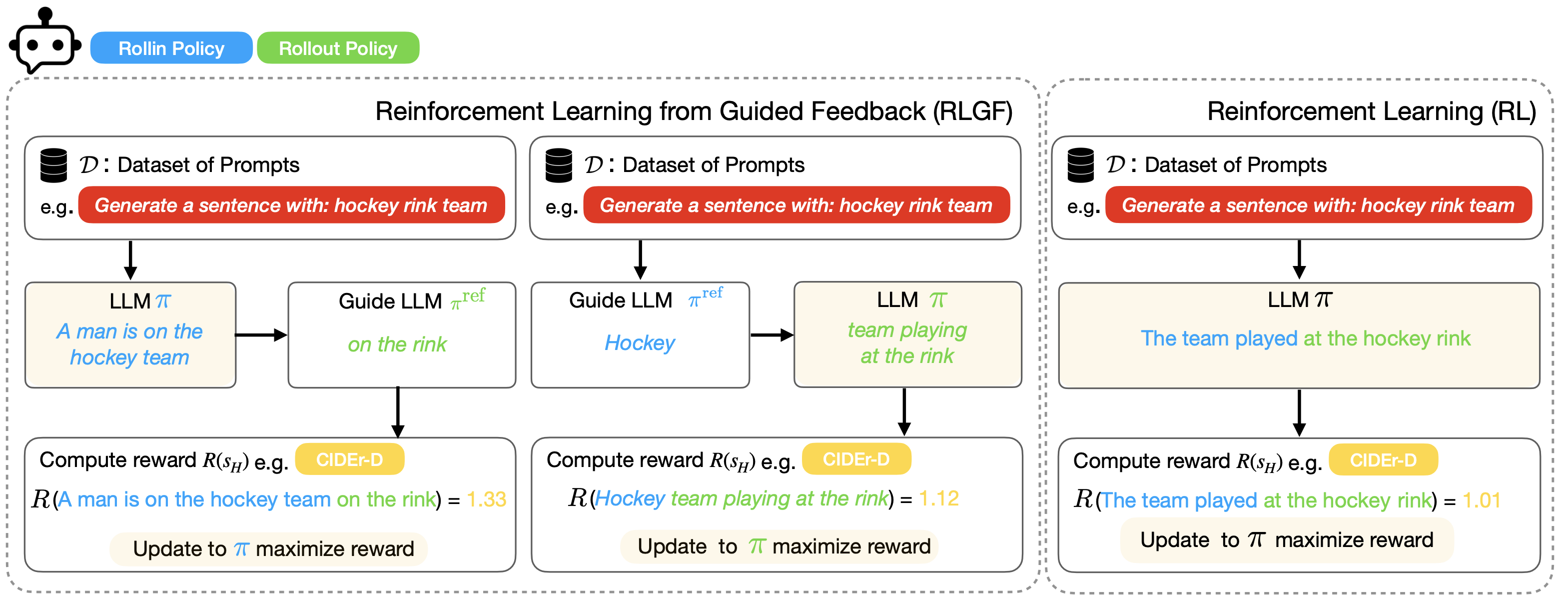
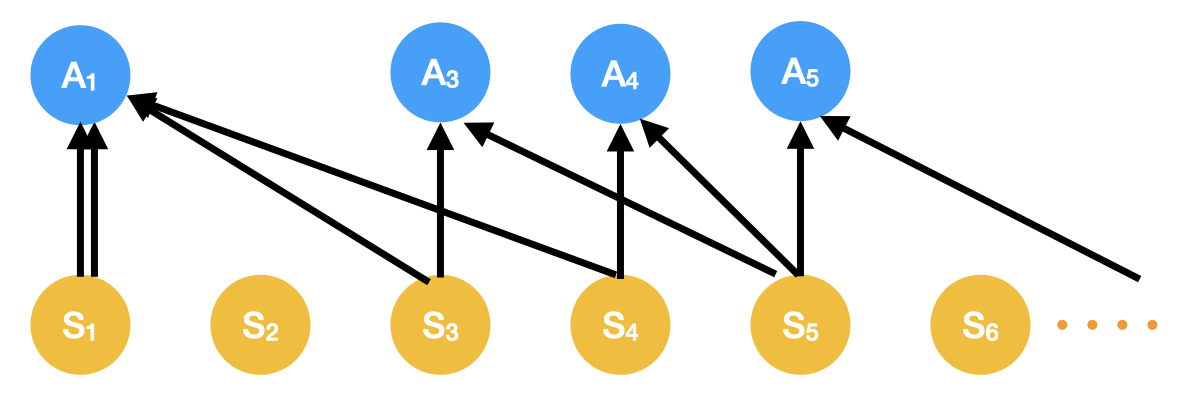
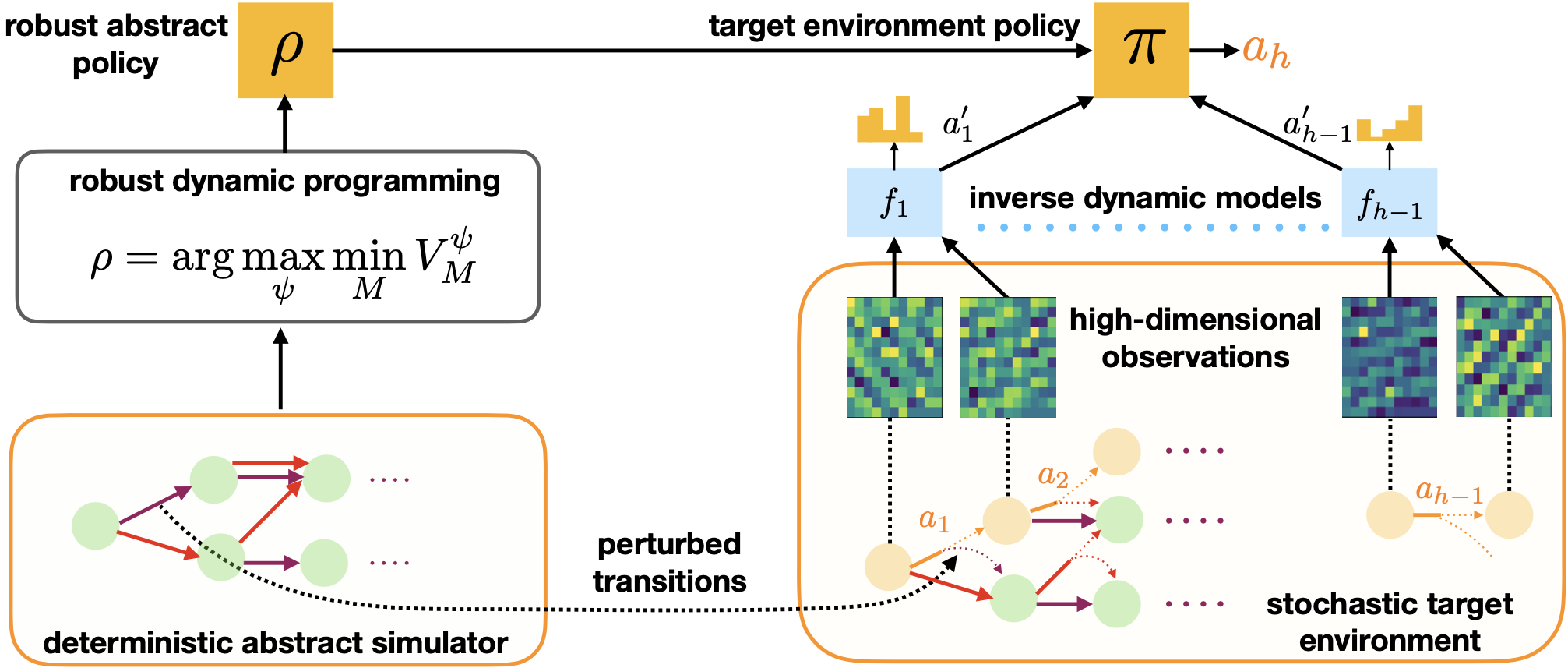
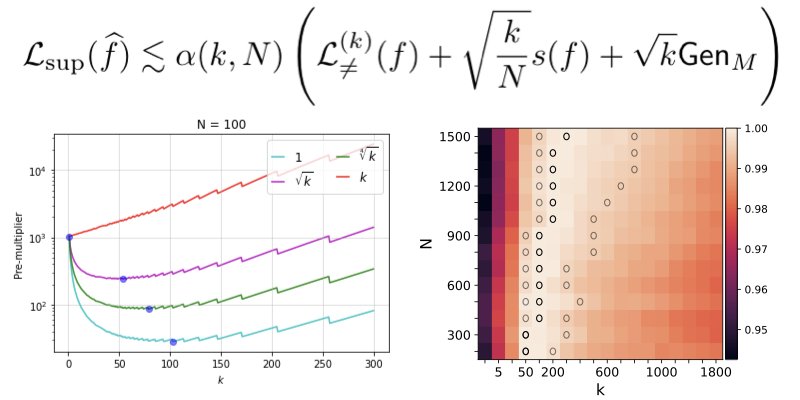
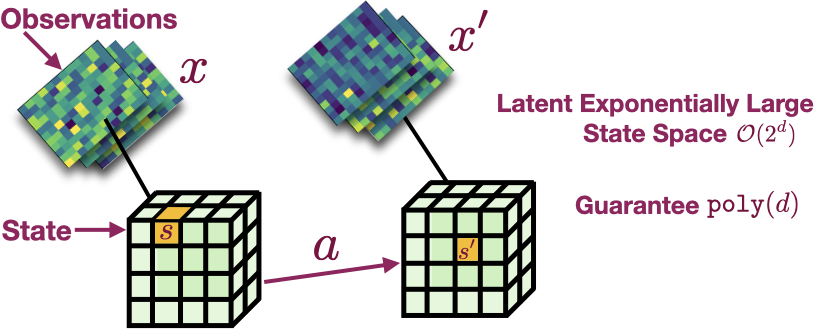
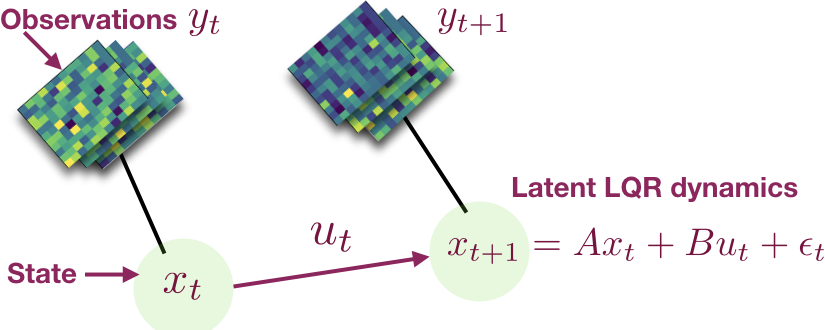
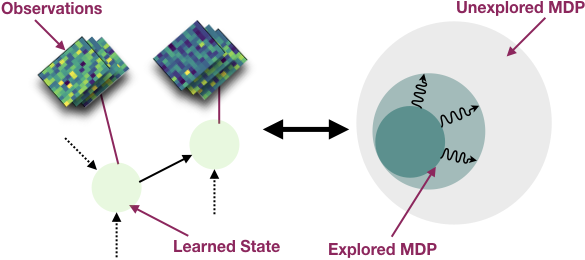
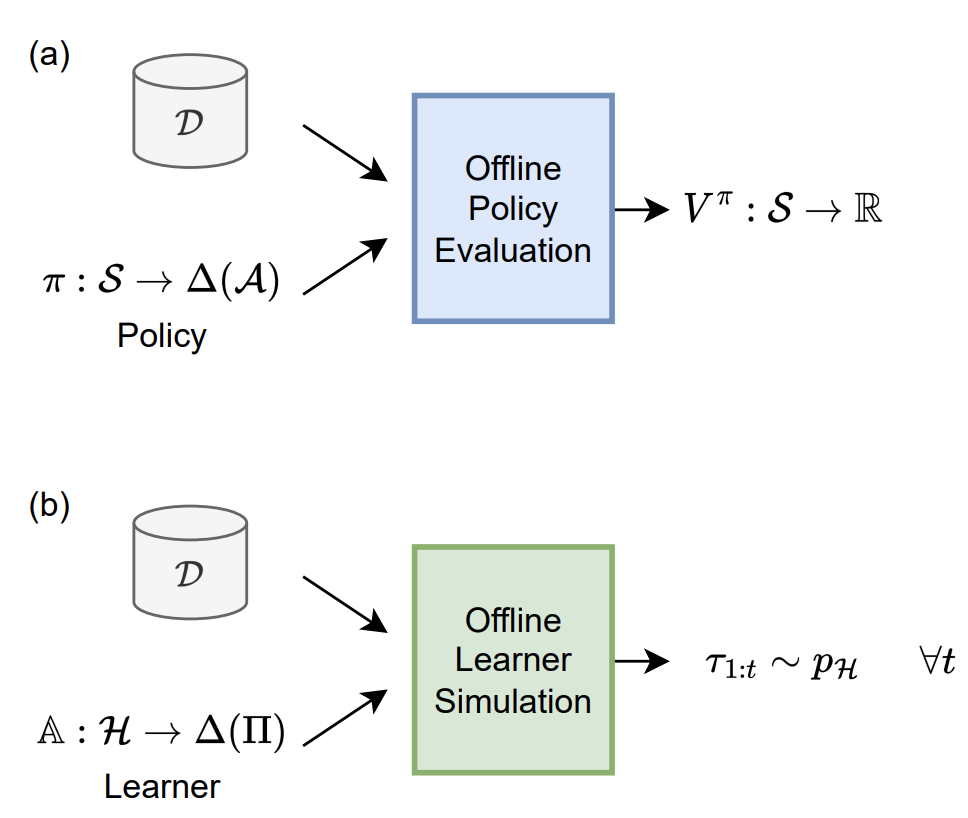
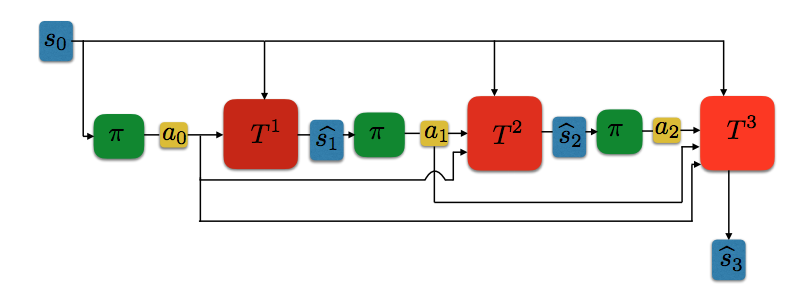
Interactive Learning (Learning Algorithm): I am interested in developing both practical and efficient algorithms for training agents. In particular, my recent focus has been on developing algorithms for fine-tuning agents such as LLM (arXiv 2023). I am interested in developing algorithms that are provably-efficient, or use insights from theory to solve real-world challenges. My representative work on this agenda includes a list of recent RL algorithms for problems with complex observations that are provably sample-efficient and computationally-efficient: the Homer algorithm (ICML 2020), RichID algorithm (NeurIPS 2020), FactoRL Algorithm (ICLR 2021), and PPE algorithm (ICLR 2022).
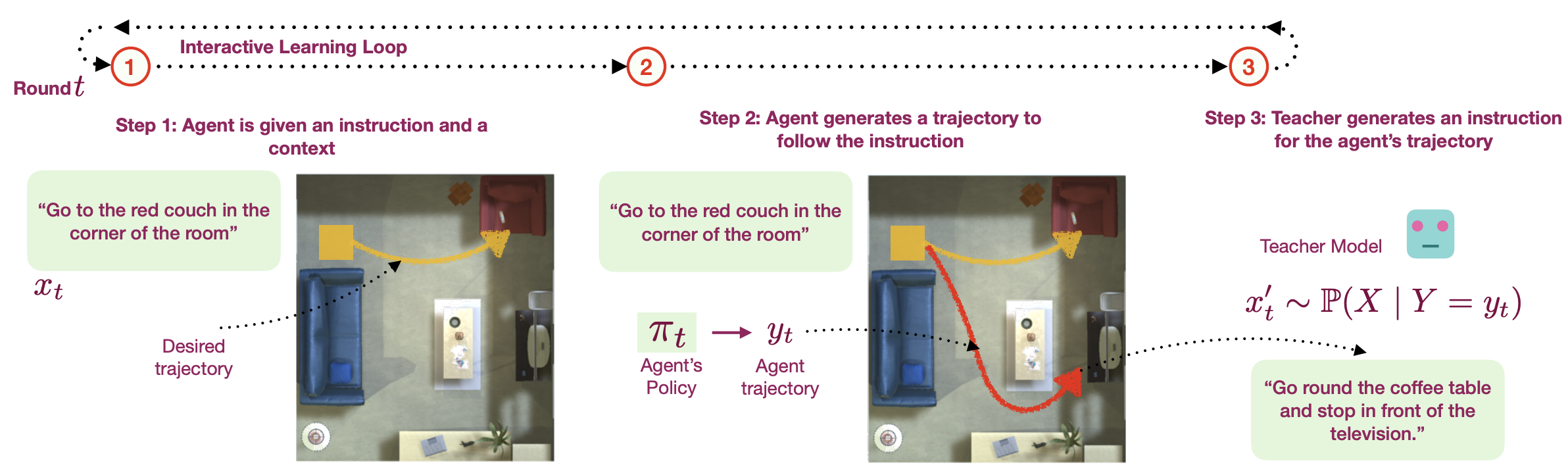
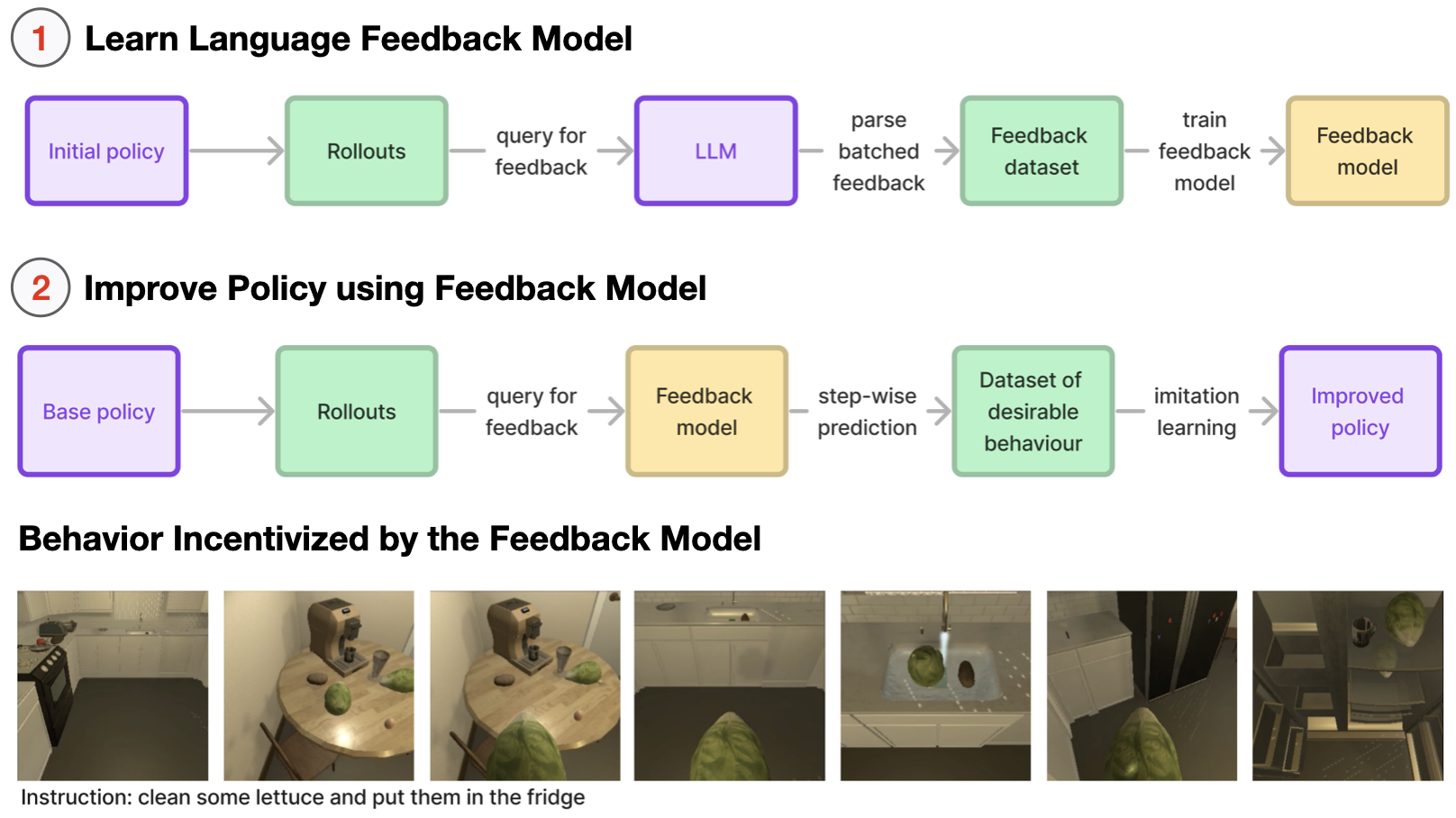
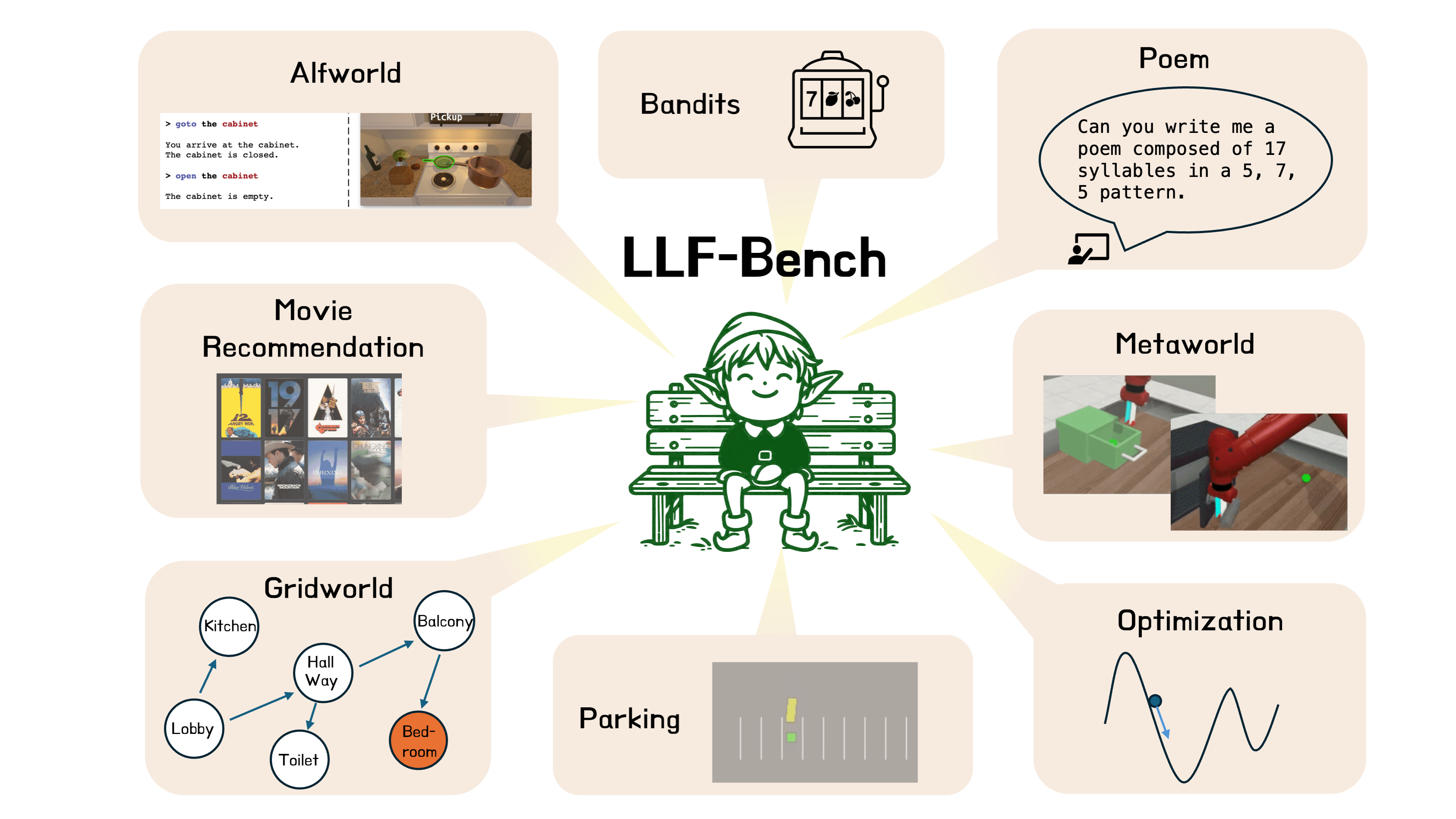
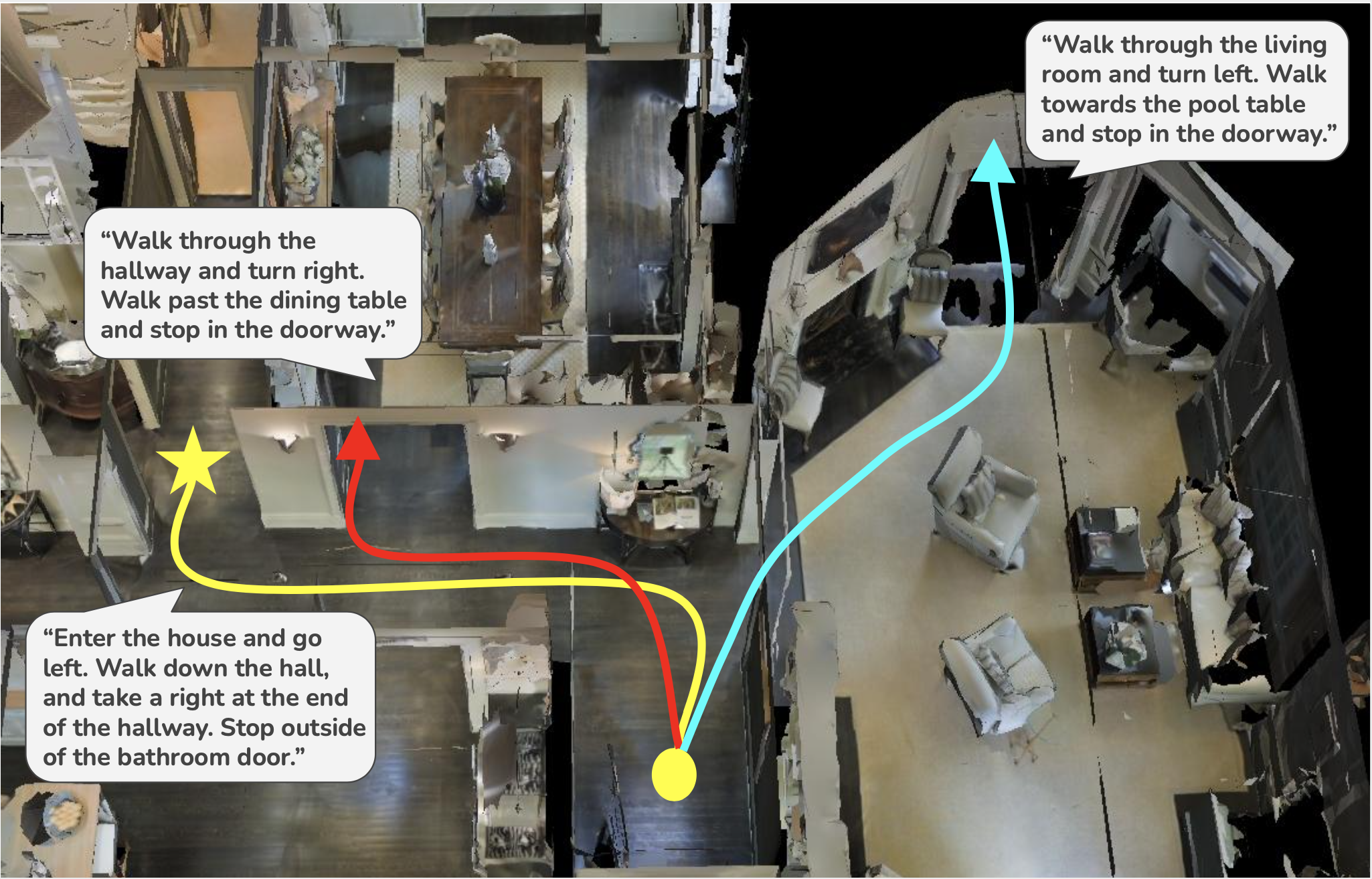
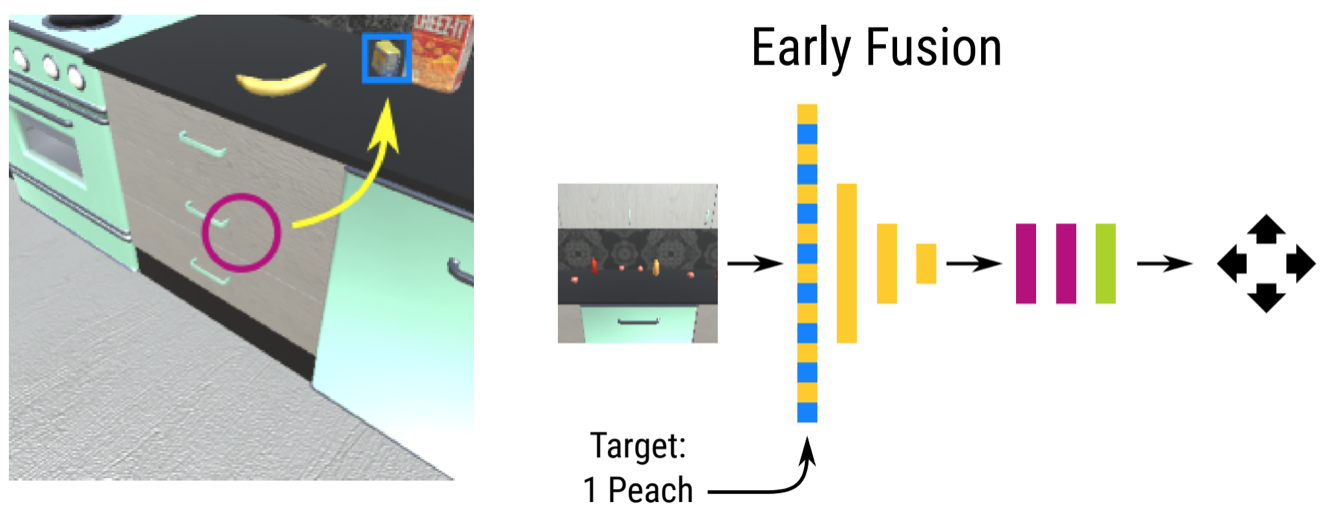
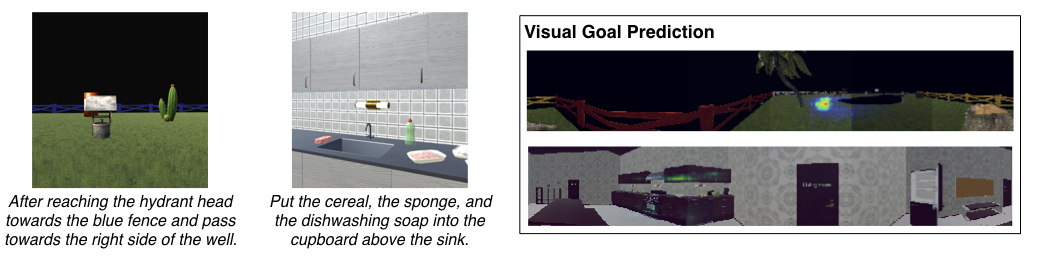
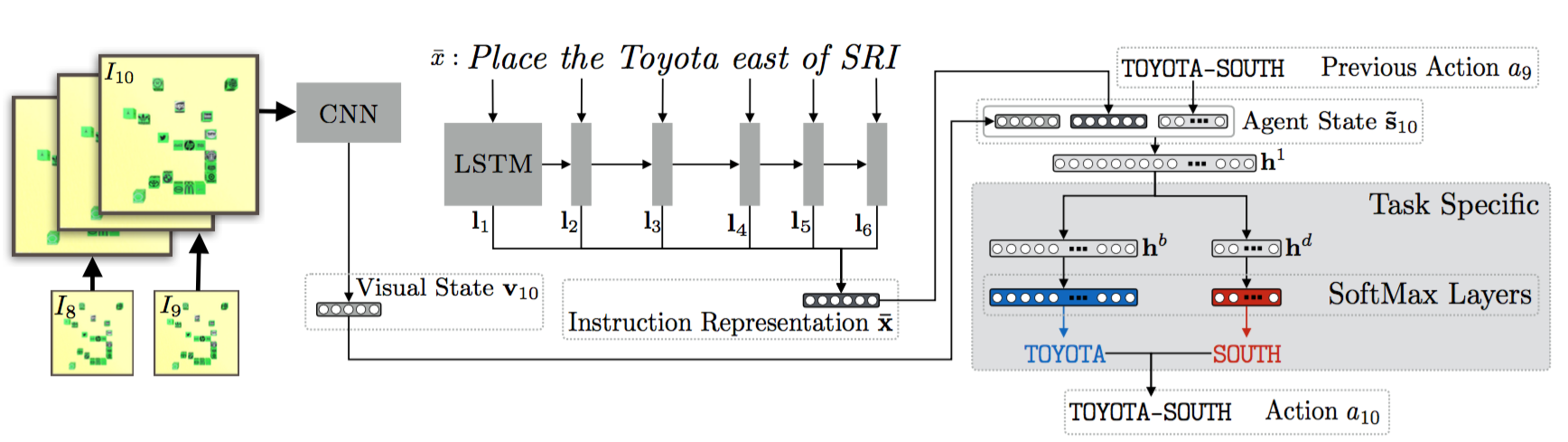
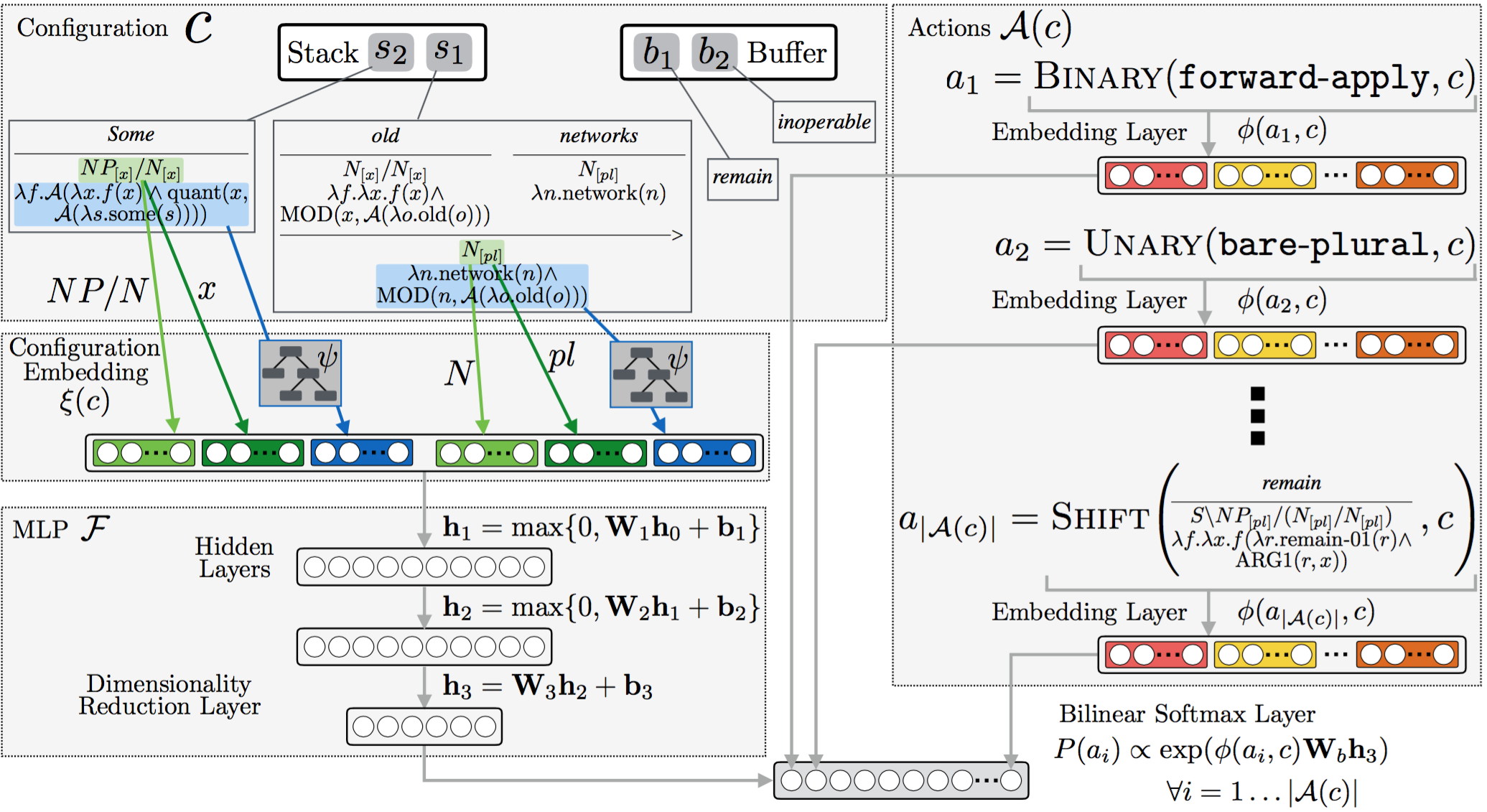
Language Feedback (Learning Signal): Natural language is an expressive medium for training and controlling agents that can be used by most humans. I am interested in developing agents that can understand and execute instructions in natural language, and also be trained using these mediums. Representative work on this agenda include the EMNLP 2017, EMNLP 2018, CoRL 2018, and CVPR 2019 papers on developing agents that can follow natural language instruction, and our recent Learning from Language Feedback (LLF) Benchmark (arXiv 2023) and the ICML 2021 paper that trains these agents using just natural language.
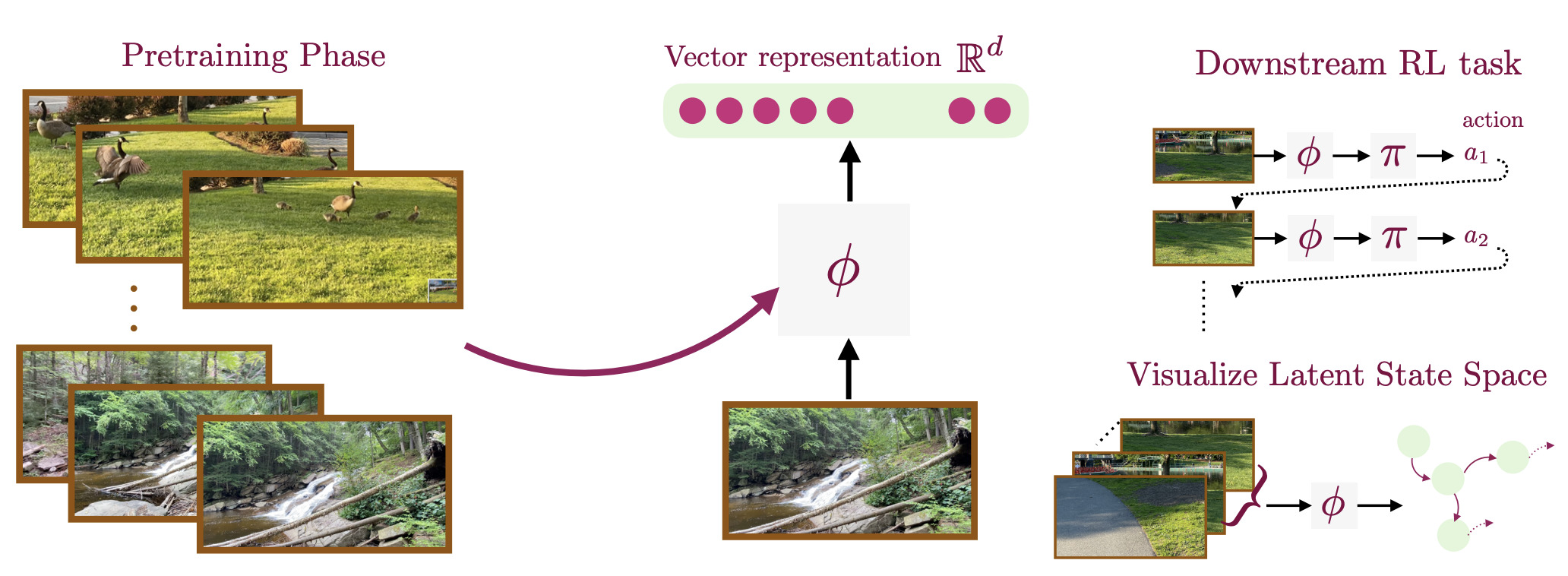
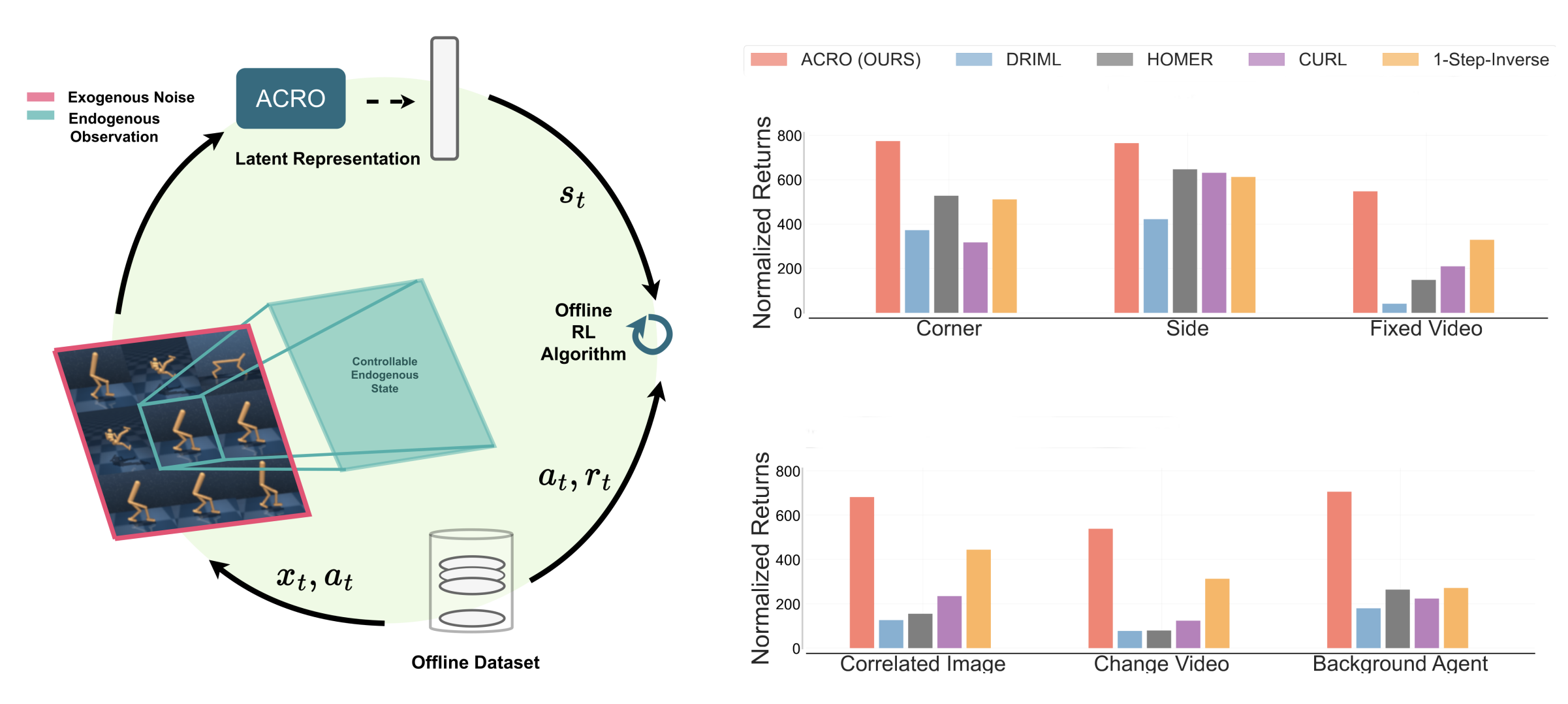
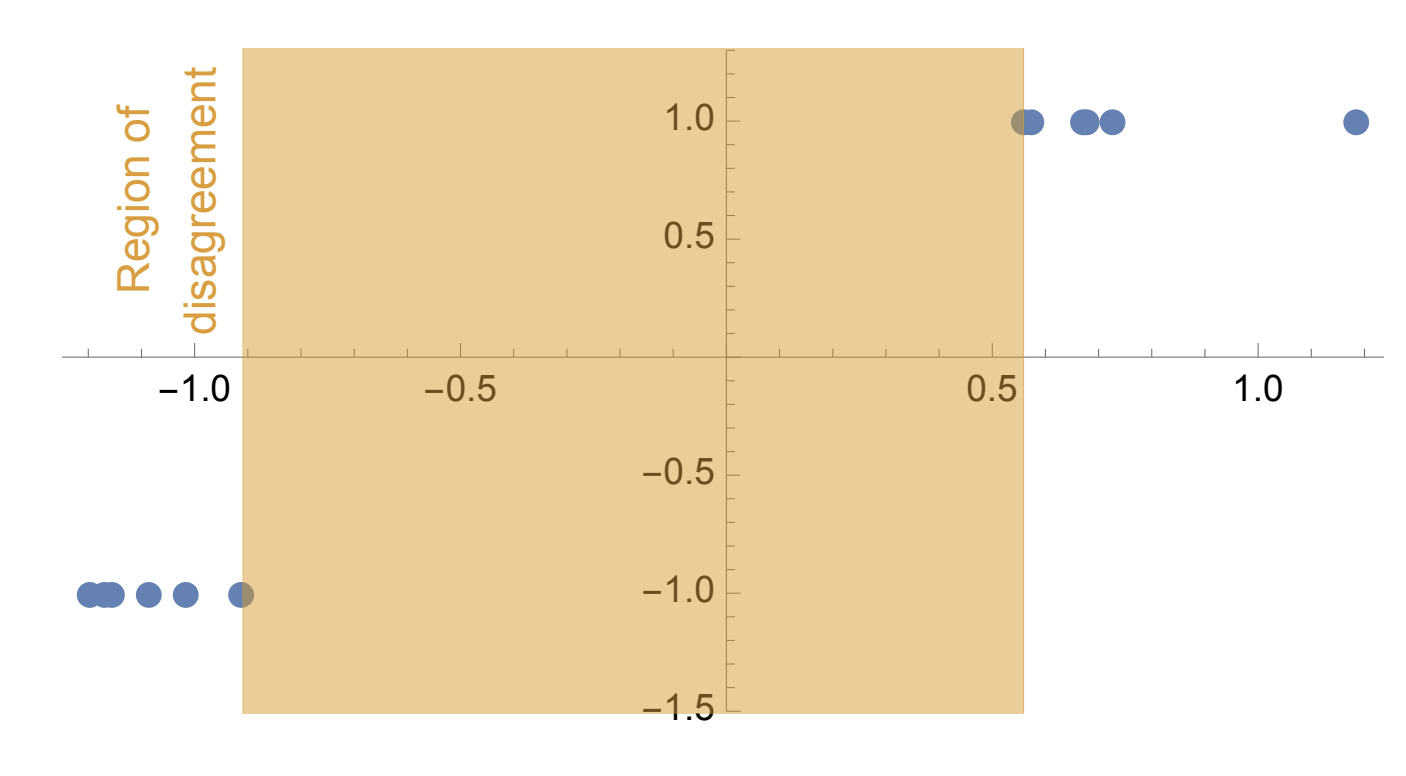
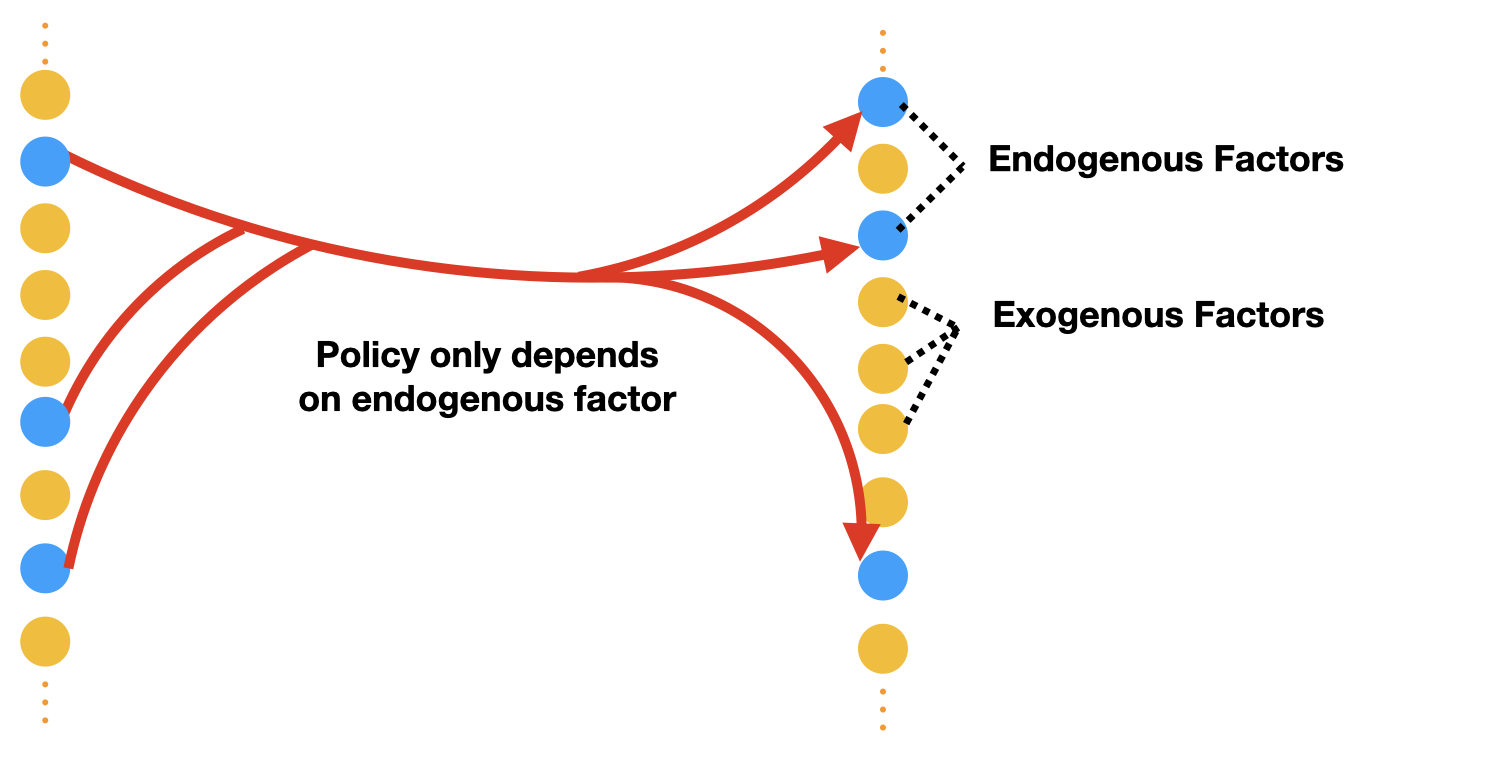
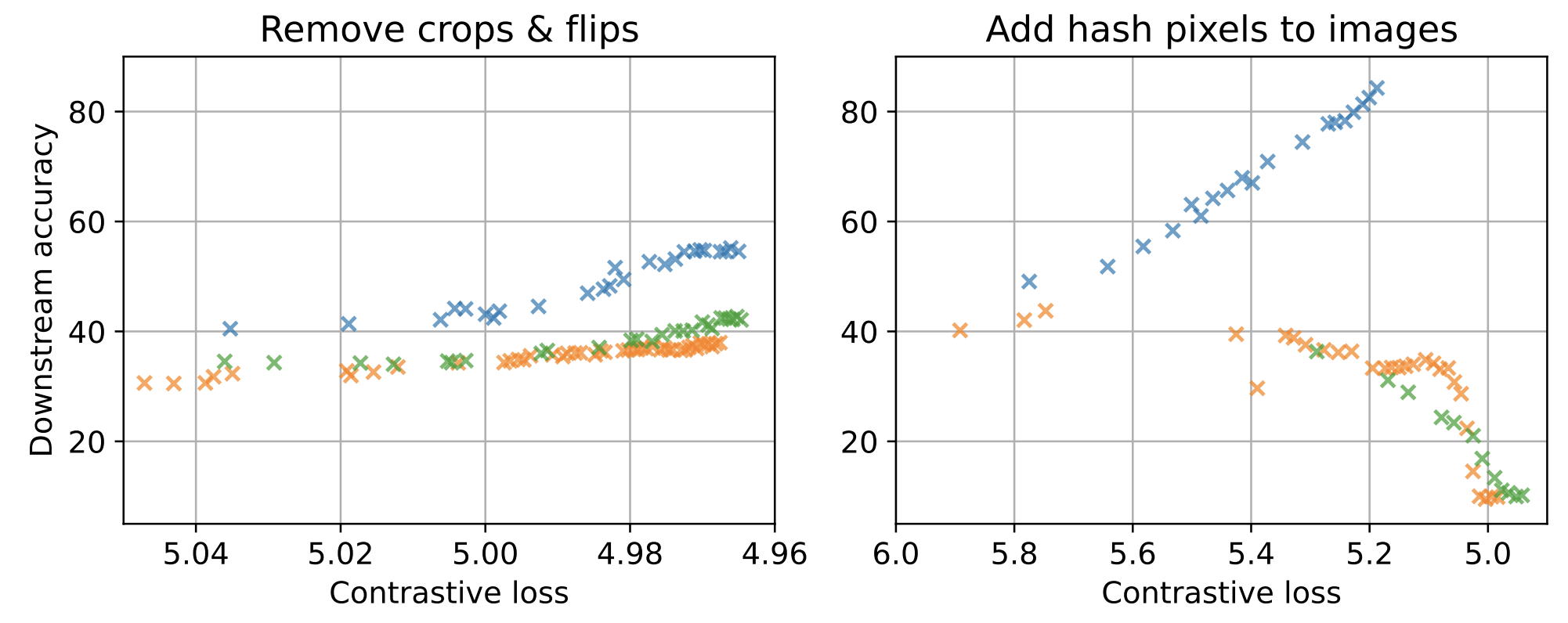
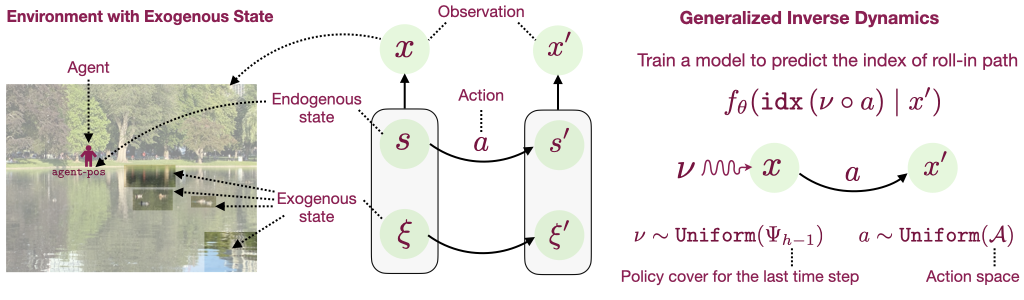
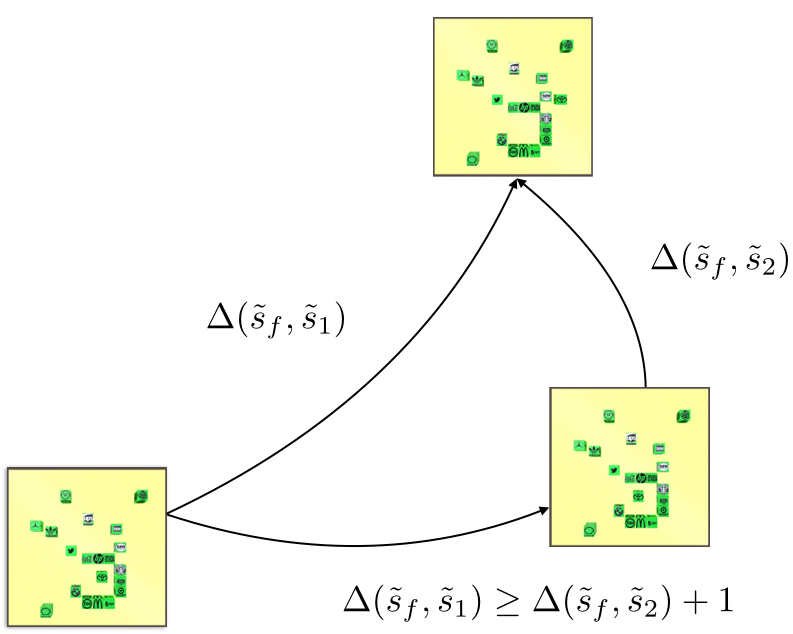
Representation Learning (Model): An agent needs to learn the right representation of the world to make decisions. E.g., a multi-modal LLM may embed image in a certain way to generate an action or caption. This choice of embedding/representation is very important. I am interested in developing the theory and practice of representation learning methods for training these embeddings, specially, using self-supervised learning. Representative work includes our recent paper at ICLR 2024 (Spotlight) for training representations using video data, and AISTATS 2022 and ICML 2022 on understanding the behavior of contrastive learning. I am also interested in understanding representations, and a representative work on this is our recent paper on the LASER method at ICLR 2024 for probing and improving LLM reasoning.
Beyond my main agenda, I also have interest in a diverse range of topics including language and vision problems, semantic parsing, statistical learning theory, and computational social science.
Bio: I am a Senior Researcher at Microsoft Research, New York. I received my PhD in computer science from Cornell University (2019) and my bachelors in computer science from Indian Institute of Technology Kanpur (2013).
Quick Links: MSR Reinforcement Learning, Intrepid Code Base, CIFF Code Base, Math for AI, My Blog, RL Formulas